Benchmarking Large Language Models on NVIDIA H100 GPUs with CoreWeave (Part 1)
Por um escritor misterioso
Descrição
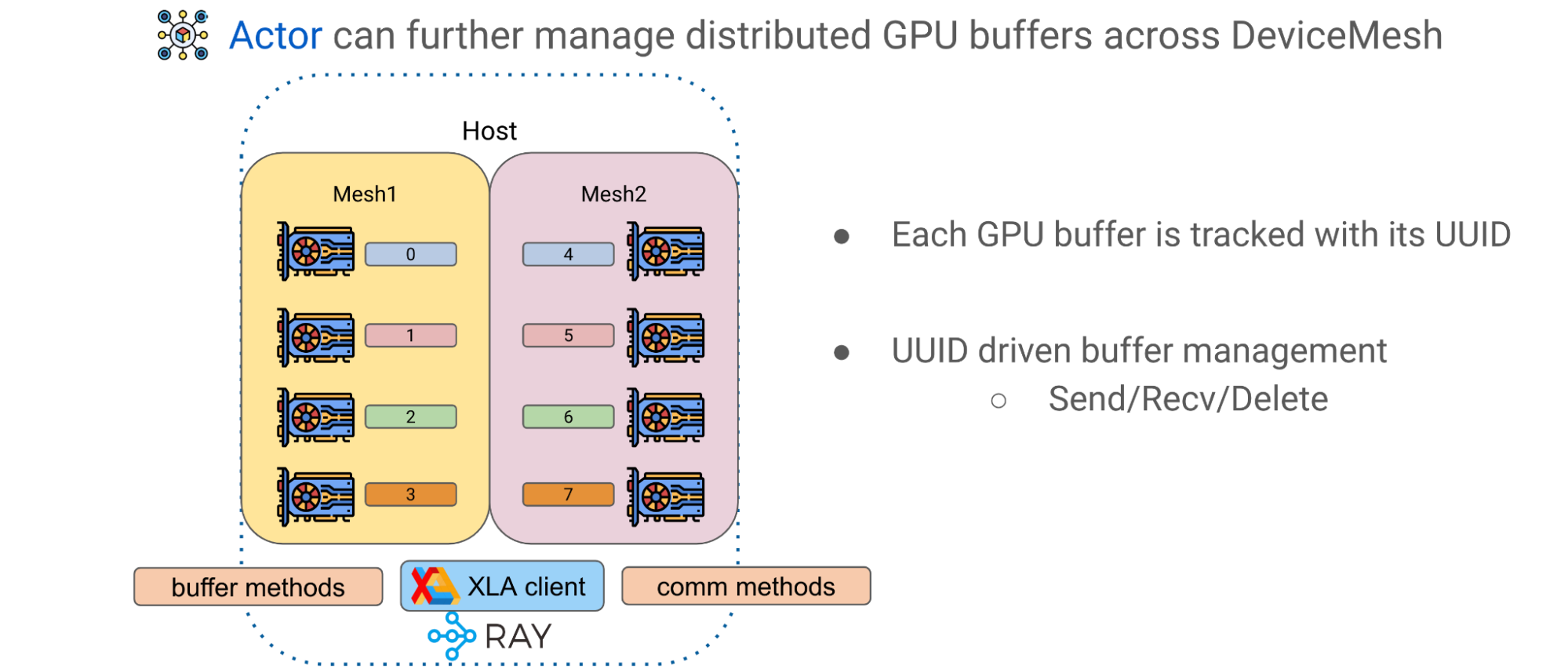
High-Performance LLM Training at 1000 GPU Scale With Alpa & Ray
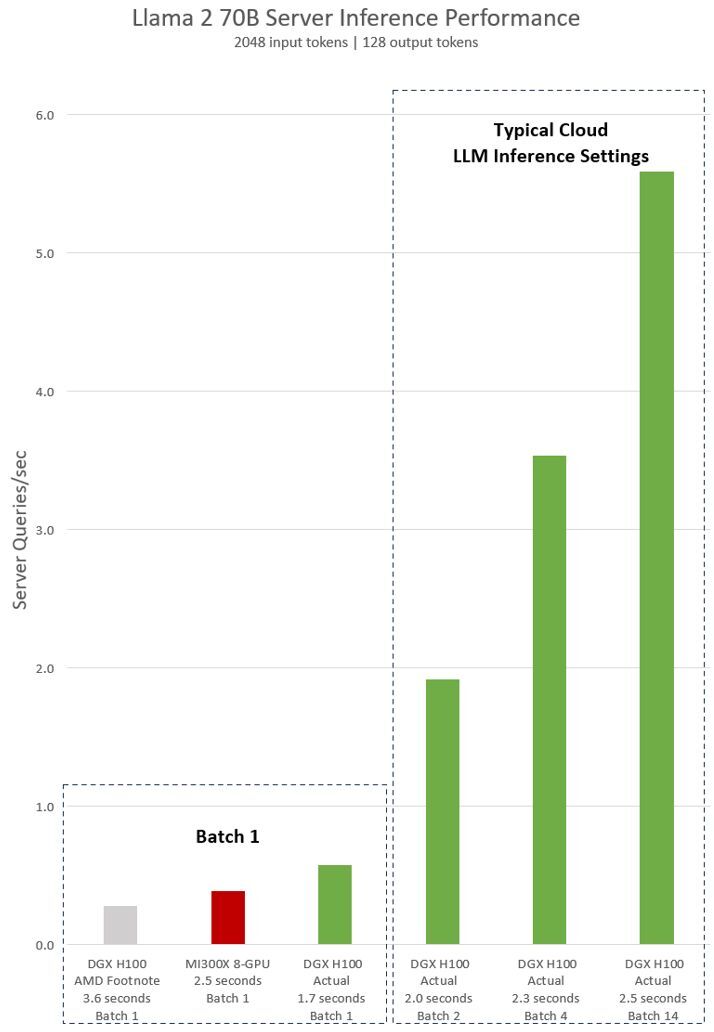
Achieving Top Inference Performance with the NVIDIA H100 Tensor Core GPU and NVIDIA TensorRT-LLM
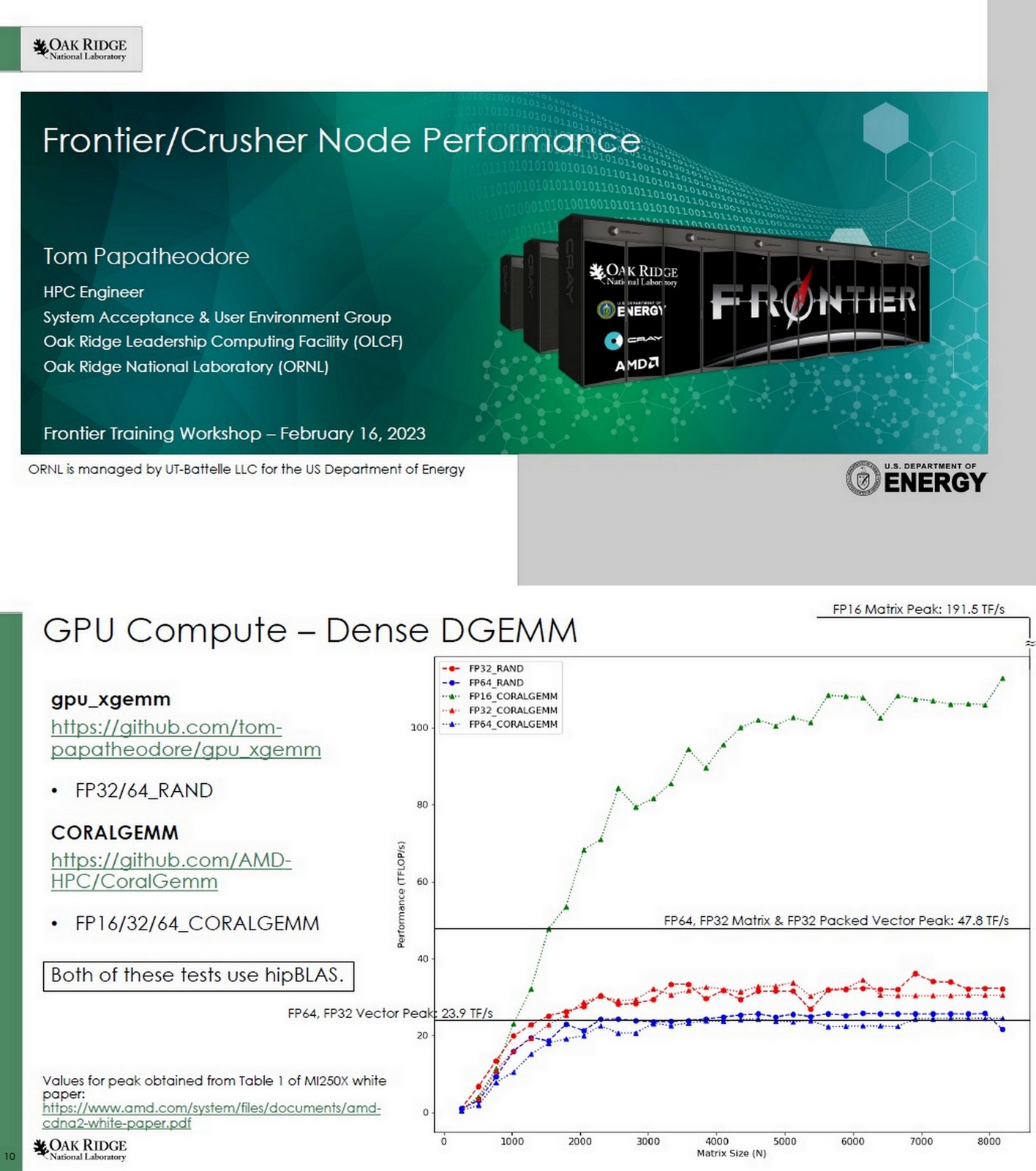
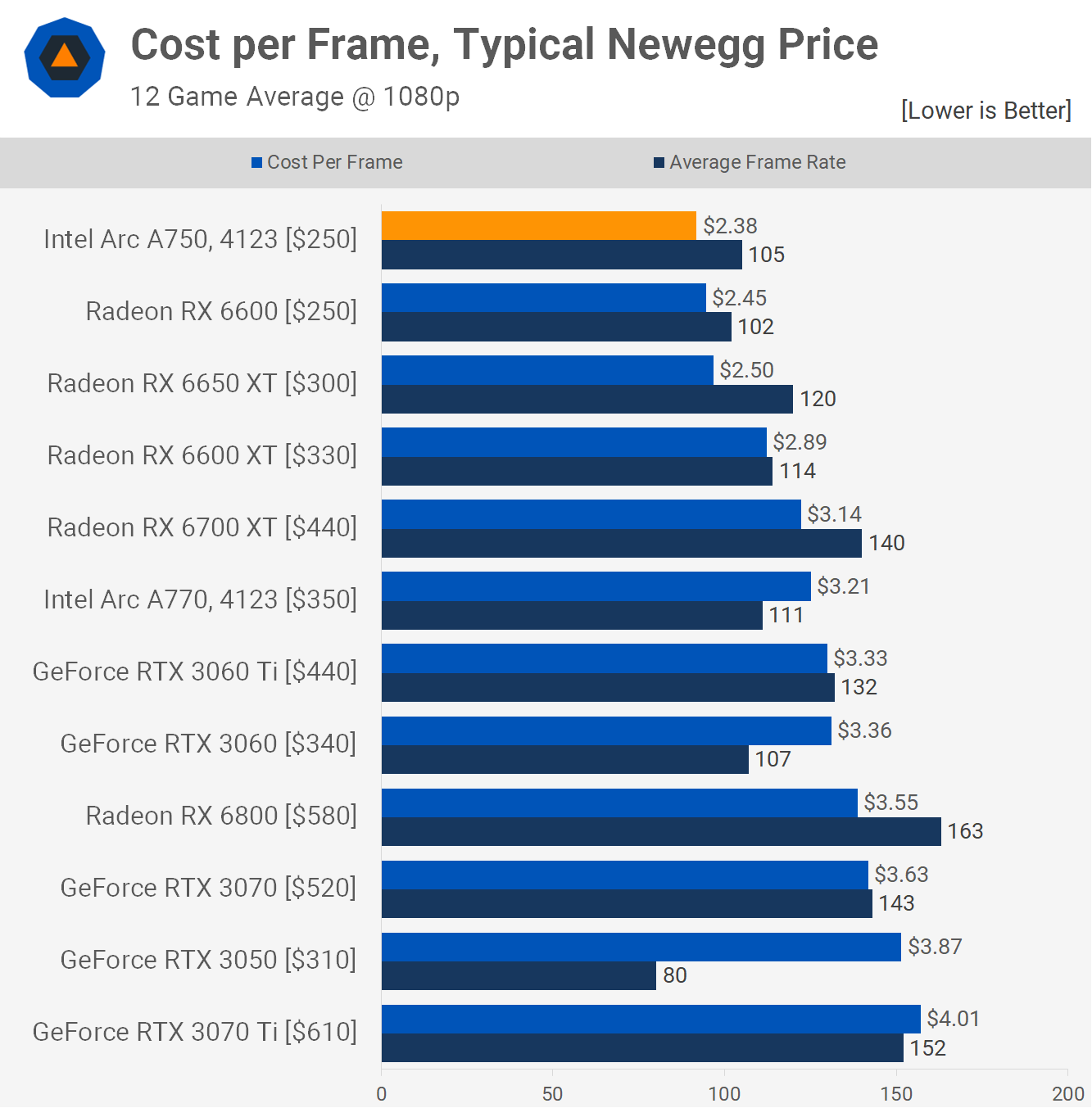
OGAWA, Tadashi on X: => Benchmarking Large Language Models on NVIDIA H100 GPUs with CoreWeave, Part 1. Apr 27, 2023 H100 vs A100 BF16: 3.2x Bandwidth: 1.6x GPT training BF16: 2.2x (

J.Vikranth Jeyakumar on LinkedIn: GitHub - NVIDIA/TensorRT-LLM: TensorRT-LLM provides users with an…

Nvidia sweeps AI benchmarks, but Intel brings meaningful competition

MLPerf Training 3.0 Showcases LLM; Nvidia Dominates, Intel/Habana Also Impress
.png)
In The News — CoreWeave
Taking AI #INFRA - 1 - Securitiex on Substack

Hagay Lupesko on LinkedIn: #nlp
de
por adulto (o preço varia de acordo com o tamanho do grupo)