The average number of unique states visited by AlphaZero and Go-Exploit
Por um escritor misterioso
Descrição

AlphaGo Zero: Mastering the Game of Go Without Human Knowledge
What is Reinforcement Learning anyways?, by Martin Klissarov, Apache MXNet
When Alpha Zero is making seemingly bizarre moves in chess is it actually predicting what its opponent will do (calculating possibilities), or is it setting up its own attack/defense based on positional
Will AlphaZero become smarter and smarter forever, if it plays chess against itself for unlimited times? - Quora

Even Superhuman Go AIs Have Surprising Failure Modes — LessWrong
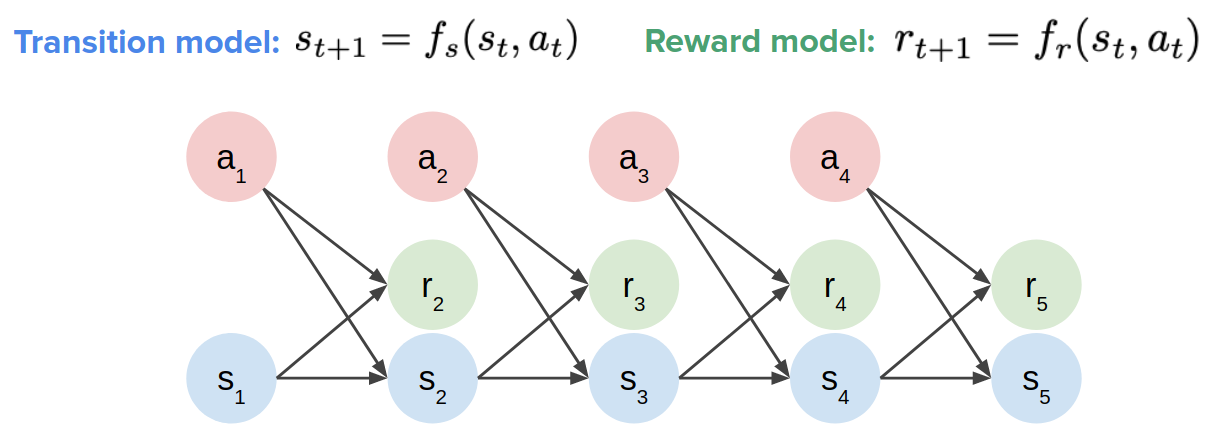
Model-Based Reinforcement Learning (MBRL), by Isaac Kargar

Value targets in off-policy AlphaZero: a new greedy backup

Monte-Carlo Graph Search for AlphaZero – arXiv Vanity

PDF) A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
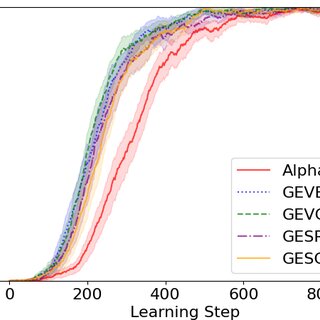
AlphaZero and Go-Exploit's win rates against MCTS-Solver 10x and 1000x

Simple Alpha Zero
de
por adulto (o preço varia de acordo com o tamanho do grupo)